在分析 Feign 源码的时候,我们看到 Feign 构建代理对象是分了几层的,一层是选择 Builder,Feign.Builder 或者是它的子类 HystrixFeign.Builder;接下来两个 Builder 会选择不同的动态代理类创建逻辑,一个是 ReflectiveFeign.FeignInvocationHandler 或者是 HystrixInvocationHandler。两者的区别主要是直接用 SynchronousMethodHandler 的 invoke 方法,或者是将 invoke 混合起来做成 HystrixMethod。如果排除掉 fallback 的情况,两者应该是一致的,即 SynchronousMethodHandler 的 invoke。其中 Retry 逻辑是包含在 SynchronousMethodHandler 里面。所以使用了 Feign + Hystrix +Retry 后,整体 client 的包含逻辑是如下图的。
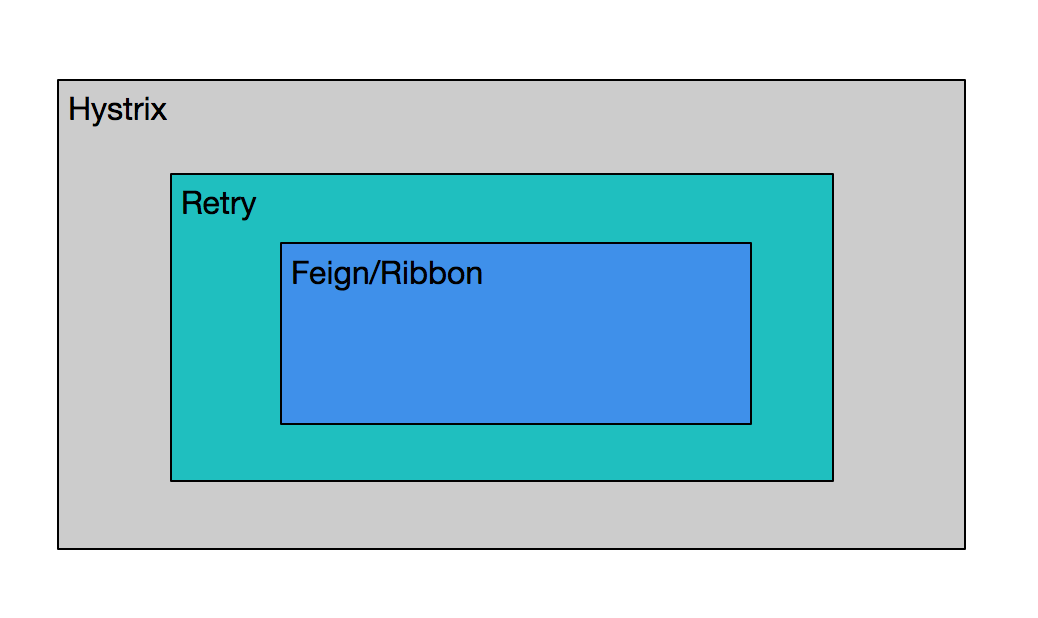
以设计意图来说,Feign Client 的配置关注在每次 Http Request 上,Retry 关注的是 Feign Client 出问题以后的 Retry 逻辑,而 Hystrix 关心的是整个调用何时能成功,出错了如何 fallback,所有调用的并发控制,是否要熔断终止调用等问题。
所以在配置 Feign Client 的超时时,会发现一些配置情景可能跟直觉不同。假设当前有一个 User Service,它有两个实例,一个实例在4s 后返回 User 列表,另一个实例在8s 后返回 User 实例。我们希望能够在访问一个实例超时后自动 Retry 另一个,而且当两个都超时后 fallback。
我们先配置一下 Feign Client 的超时配置。关于 Feign Client 的配置还有个比较有趣的现象,尽管对于全局的 Feign Client 已经能够通过配置文件来进行默认属性的配置,但是这个 pull 并没有进入最新 GA 的 Dalston SR3版本。该 pull 在这里 `FeignClient Configuration Properties by khannedy · Pull Request #1942 · spring-cloud/spring-cloud-netflix · GitHub ,可以看到该 pull 被安排进了 Edgware 版本。当前项目使用还是用的 Dalston,所以只能用 configuraiotn 的形式来为每个 FeignClient 单独配置。
@Configuration
public class FeignClientConfiguration {
@Bean
public Request.Options options() {
return new Request.Options(
6000,
6000
);
}
}
如此配置以后会发现,大概1s 时间就直接进入 fallback 了。因为这时候开启了 hystrix,而 hystrix 的默认 timeout 是1s。我们先把 hystrix 的 timeout 关闭。hystrix.command.default.execution.timeout.enabled=false,再测试。现在就可以了,客户端会去访问 User Service,并且在访问到8s 的那个实例时如期超时,并且 Retry 会将它转向下一个实例,等待4s 后返回结果。
现在我们把 hystrix 的 timeout 再次开启,将其也设置为6s,会发生什么?
hystrix.command.default.execution.timeout.enabled=true
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds = 6000
结果就是当前如果轮询到了8s 的实例,则进入 fallback,而轮询到了4s 的实例就能正常返回结果。看起来似乎 Retry 没有生效。实际上根据我们上面的分析,并不是这样的,而是因为 Hystrix 控制的是整个执行的耗时,它不在乎你是否要 Retry,或者 Retry 几次,总要有个人看着你的完整请求耗时时间。所以如果我们把 Hystrix 的超时时间,调整为 Feign Client 的两倍,即12s。这样能保证 Feign Client 起码能做完两次请求。在我们的情况中,第一次请求会在6s 中的时候由 Feign Client 主动终止,而第二次请求会在4s 后返回,总体10s,并不会触发 Hystrix 的 timeout,所以能够正常工作。结果也是如此。